Troubleshooting network issues can be tricky, and adding a load balancer into the mix creates additional challenges. Trying to discern if the load balancer is simply dropping packets, changing the packets in some way, or adding more latency can be difficult. There are some tricks of the trade that can be employed to make finding the issues easier.
The first step of any troubleshooting exercise is to check the statistics of the entity in question. However, if those statistics state that everything is fine, and the network issue is still occurring, then you have to bring in the "Switzerland" of the troubleshooting world -- packet analysis. While there are many excellent paid products out there for packet analysis, I prefer the open source Wireshark.
When analyzing an issue that involves a load balancer, the first question to be answered is whether the load balancer is in transparent mode. In transparent mode, the load balancer will pass the original client's IP as the source IP. In non-transparent mode, the load balancer will NAT the requests to the servers with the load balancer's virtual IP address, or VIP. Non-transparent mode is the most common implementation.
Now you are ready to take the trace files. In a perfect world, you would have taps to insert at each of the points in the diagram below. If you don't have taps, you can capture traffic using a SPAN or mirror port on the switch. Or you can use tcpdump on the inbound and outbound ports of the firewall and load balancer. The key is to capture packets in all four places at one time to look at conversations from four different vantage points.
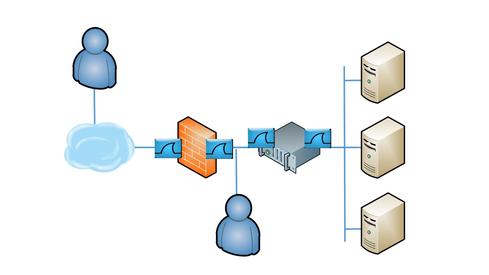
After you capture the data, you must find single conversations that appear in all four of the trace files. Normally, you would filter for the two IP addresses in question and be done. But, remember the load balancer performs NAT on the server side, so filtering for the client IP won't work on the server-side trace.
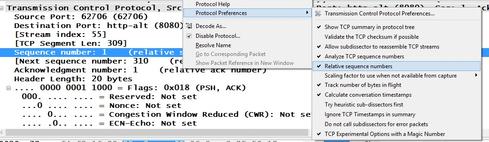
Going up to Layer 4 solves the problem. You can filter on the sequence number in the TCP header. Be careful, though; Wireshark shows relative sequence numbers by default, and you may end up with hundreds of packets with sequence number 1. The key is to turn off relative sequence numbers in the TCP preferences. Just uncheck the selection and the actual billions decimal number displays instead of the one relative to the beginning of the conversation. Once you filter for the same sequence number in all four trace files, you should have one packet in each file.
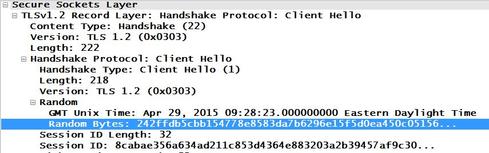
The tricky part comes in if your load balancer creates its own packets on the NAT side to the server. The sequence field would then no longer be the same from end to end. The best field to use in that scenario is one that is unique in the application layer. For HTTP, I recommend the Cookie field, and for HTTPS, the Random Bytes field in the Client Hello.
Finally, you are down to a single conversation captured in multiple places and can analyze the traces. First, look for packet drops. In Wireshark Expert Analysis language, those will be flagged as "Previous segment not captured." This will appear in one or more of the trace files, but not all. If you see the response from the server in the outbound side of the firewall trace, but not the inbound, you know packets are being dropped by the firewall, for example.
After looking for packet drops, check the TCP handshake to ensure the TCP options have not been tampered with along the path. Window scaling and Selective Acknowledgements have a tendency to disappear when a box along the path creates its own packet versus passing along transparently. Those two options are important for throughput and should not be stripped.
The last issue to look for in the traces is high delta times. By capture data at four different points, you will truly be able to see what, if anything, is adding latency. Start by looking at the handshake. Use the time between the synchronization request (SYN) and the synchronization response (SYN/ACK) as a baseline. Look at the rest of the requests and responses in the trace taken inbound of the firewall, closest to the client.
For those request/response combinations that have a delta of one second or more, walk through each trace until you find which port is adding the latency. Is it a firewall whose CPU is spiking? Is it a load balancer that is having trouble tracking its NAT table? Maybe it's the server with too many concurrent connections. Going through the traces will tell you where the trouble is, and where it is not.
Setting up packet captures may take up precious time during a network firefight, but it saves enormous time in the long run.







