As the number of virtual machines (VMs) in a data center places an increasing load on back-end shared storage, performance bottlenecks arise. This is driving a surge in demand for solid-state storage (i.e. flash), which can improve storage access times by 1000x or more.
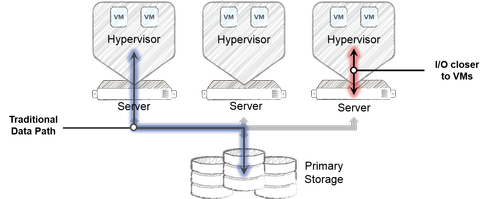
But another performance challenge also exists: network latency. Every transaction going to and from a VM must traverse various chokepoints, including a host bus adapter (HBA) on the server, LAN, storage controllers, and a storage fabric. To address this, many companies are placing active data on the host instead of on back-end storage to shorten the distance (and time) for each read/write operation (see Figure 1).
Figure 1: Moving data closer to VMs at the server tier to reduce latency
Hyperconvergence puts solid-state storage inside servers. In this respect, it brings incremental performance gains to several applications, like VDI. But architecturally, it introduces various drawbacks, particularly around flexibility, cost, and scale. Perhaps most significantly, it causes substantial disruption to the data center. Let's look a little closer at these hyperconvergence challenges and how to overcome them.
Hyperconvergence hangover
As mentioned above, hyperconvergence improves VM performance by leveraging server flash for key storage I/O functions. But combining the functions conventionally provided by two discrete systems -- servers and storage -- requires a complete overhaul of the IT environment currently in place. It creates new business processes (e.g. new vendor relationships, deployment models, upgrade cycles, etc.) and introduces new products and technology to the data center, which creates disruption for any non-green field deployment.
For example, the storage administrator may need to re-implement data services such as snapshots, cloning, and replication, restructure processes for audit/compliance, and require training to become familiar with a new user interface and/or tool.
Another major challenge with hyperconvergence stems from the modularity often touted as one of its key benefits. Because the de-facto mode of scaling a hyperconverged environment is to simply add another appliance, it restricts the ability of the administrator to precisely allocate resources to meet the desired level of performance without similarly adding capacity. This might work for some applications where performance and capacity typically go hand in hand, but it's an inefficient way to support other applications, like virtualized databases, where that is not the case.
For instance, let’s consider a service supported by a three-node cluster of hyperconverged systems. In order to reach the desired performance threshold, an additional appliance must be added. While the inclusion of the fourth box has the desired performance outcome, it forces the end user to also buy unneeded capacity. This overprovisioning is unfortunate for several reasons: It's an unnecessary hardware investment that can require superfluous software licenses, consume valuable data center real estate, and increase environmental (i.e. power and cooling) load.
Finally, hyperconverged systems restrict choice. They are typically delivered by a vendor who requires the use of specific hardware (and accompanying software for data services). Or they are packaged to adhere to precisely defined specifications that preclude customization. In both scenarios, deployment options are limited. Organizations with established dual-vendor sourcing strategies or architects desiring a more flexible tool to design their infrastructure will need to make significant concessions to adopt this rigid model.
A new storage model
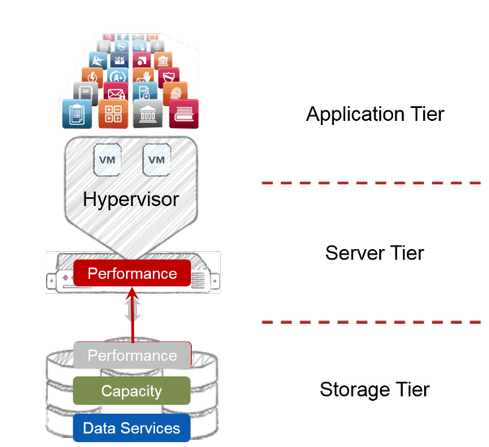
A new “decoupled” architecture has emerged that addresses these issues. Like hyperconvergence, it puts storage performance in the server, using high-speed server media like flash (and RAM). But unlike hyperconvergence, it leaves capacity and data services in shared storage arrays (see Figure 2).
Figure 2: Decoupling storage performance from capacity and data services
There are several benefits that come with separating storage performance from capacity:
- Fast VM performance by putting storage intelligence in high-speed server media. Unlike hyperconverged systems, this can be flash, RAM or any other technology that emerges in the coming months/years.
- No vendor lock-in, as decoupled architectures leverage any third-party server and storage hardware.
- Cost effective scale-out. Additional storage performance can be easily added simply by adding more server media. Capacity is handled separately, eliminating expensive overprovisioning.
- No disruption. Decoupled software is installed inside the hypervisor with no changes to existing VMs, servers or storage.
- Easy technology adoption. With complete hardware flexibility, you can ride the server technology curve and leverage the latest media technology for fast VM performance (E.g. SSD, PCIe, NVMe, DRAM, etc.).
Once in place, a decoupled storage architecture becomes a strategic platform to better manage future growth. Because performance and capacity are isolated from one another in this structure, they can be tuned independently to precisely meet the user requirements. Going back to the previous example of a service supported by a two-node cluster, performance and capacity can now be added separately, as needed, to reach the desired service level without overprovisioning.
IT operators are often faced with the desire to gain a competitive edge by adopting new technology while ceaselessly looking to mitigate risk. Often, one has to be prioritized above the other. In the case of hyperconvergence, pushing the innovation envelope involves compromising flexibility and accepting institutional changes to fundamental operating procedures in the data center.
Decoupled storage architectures, on the other hand, offer the rare opportunity to take advantage of two major industry trends -- data locality and faster storage media -- to speed virtualized applications in a completely non-intrusive manner. In essence, all the performance benefits of hyperconvergence without any of the disruption.