Since the earliest caveman utterances, we humans have learned to glean meaning from noise. History is filled with classic mistranslations, but in most cases these mistranslations are merely funny. Fast forward a few millennia, and the Interwebs come along. We especially love our memes, many of which include classic mistranslations from one human language to another. For example, "All your base are belong to us," is one that is familiar to most gamers.
Now fast forward past the Stone Age, the Bronze Age, and the Industrial Age. Modern technologists are blessed to live in the Information Age, a time that just couldn't be any cooler for tech lovers. The Information Age is also the Machine Age. And machines love to talk. After all, there is so much information, yet so little time.
Today big data is the buzzword overshadowing enterprise software. Data puddles, data streams, data lakes, data oceans... How do we handle this very large and always expanding amount of machine data?
Fight fire with fire
First coined by U.S. settlers in the 19th century, "fight fire with fire" is a time-tested tactic. If you remember only one thing from this post, it will hopefully be this key point: We need to fight machines with machines. Humans simply can't keep up with all the machine data.
We've entered the brave new world of IT, and our systems are generating boatloads of machine data. The increasing focus on continuous delivery, constant updates and upgrades to software, as well and business reliance on software, mean that the use of cloud computing and virtualized networks has never been greater. And to monitor the performance and availability of these network devices and components, we look at the data they output. Just a few years ago, IDC estimated that the amount of machine data alone would grow by 15 times by 2020. So, how do you separate the signal from the noise?
Service assurance tools can leverage the power of machines with the advanced use of algorithms. We do this at Moogsoft, and one important observation has come to me repeatedly. People love to say, "Yes, I want to leverage the power of machines," yet many are afraid to let go of their old workflow habits.
We watch algorithms produce very impressive and actionable outputs, yet we still see people get stuck on the letters, entirely overlooking the spirit of the message. It's akin to watching a curmudgeonly, stickler grammar teacher analyze a passionate, moving emotional scene from a movie. The forest is missed for the trees entirely.
What would Google do?
We actually don't have to ask what Google would do, because it turns out that Google has already done it. Google knows data and is very good at it. Stephen Levy's book, Inside the Googleplex, provides an excellent description of Google's approach to Google Translate. I won't recite all that here, but I will call out that Google has led the way by deciding not to use a traditional workflow approach to language translation, and instead made a conscious decision to rely on semi-deterministic algorithms, rather than use direct, rules-based translation.
How does this relateto the modern day IT or data center manager? The ever-growing volume of event/alert data streams generated from IT components is comparable to a veritable data tsunami. This makes it overwhelming to quickly sort out the signal from noise when something goes wrong. With this in mind, an IT manager needs to understand how to leverage the power of machines (algorithms). Additionally, she also needs to break away from old habits and re-invent her incident workflow. In fact, she doesn't need as much deterministic output in her service assurance systems as she might initially think.
Google's approach
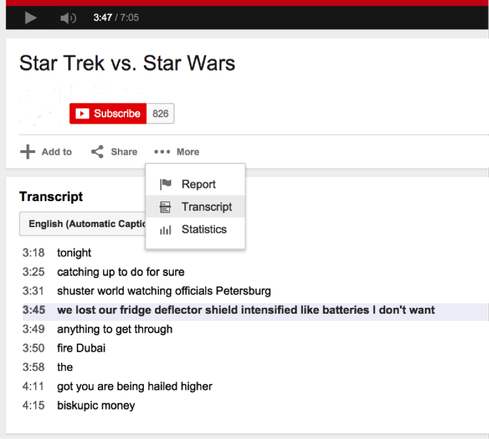
Most people are too busy watching cat videos on the Internet to actually notice what's hidden in YouTube's "More" menu. However, if you look closely at this menu, you'll notice that there is an option to show the transcript of each video. This is a perfect example of how Google and YouTube are using analytics to automate speech-to-text translations.
This is probably the best analogy I've found for what must happen with respect to re-inventing workflows around semi-deterministic algorithm outputs.
When watching a video on YouTube, often we want to find a certain spot where someone said or did something. With this in mind, we find ourselves badgering the play, pause, and forward buttons to get back to that specific place.
All we really need to do, however, is simply look at the video transcript. In nearly all cases, we can immediately detect the spot that we've been looking for. Then, you simply click on it in the translation, and automatically go to the exact instance in the video. It's that easy.
What we've noticed, however, is that many people tend to act like the curmudgeonly, stickler grammar teacher I mentioned earlier. Those stuck in old workflows will measure all of the mistyped and incorrectly translated speech-to-text in the transcript, and snidely claim that there's too much noise to rely on this approach. I call this silliness.
In the example screenshot above, I doubt there are any Star Wars or Star Trek fans who couldn't easily read the phrase, "We lost our fridge deflector shield" and understand that the space crew lost its "bridge deflector shield." And, if that's the scene you were looking for, then bingo, you've found it straight away. This phenomenon is summed up in the term "accuracy to goal vs. accuracy to info."
Improving accuracy to goal
Now, if I can optimistically and greedily hope that you remember not one, but two things from this blog, then it would be this: As we boldly go forth into the age of ever-increasing data, we have no choice but to learn to deal with semi-deterministic intelligence. We must use accuracy to goal workflows to successfully tell the difference between a space refrigerator, the Starship Enterprise, and the Death Star.