Software-defined storage is just emerging into the market place, which makes it one of the fastest evolving sectors of the IT industry. It also makes this one of the most confusing areas of technology, with extravagant hype colliding with old-fashioned FUD to obfuscate one of the most important transitions in IT.
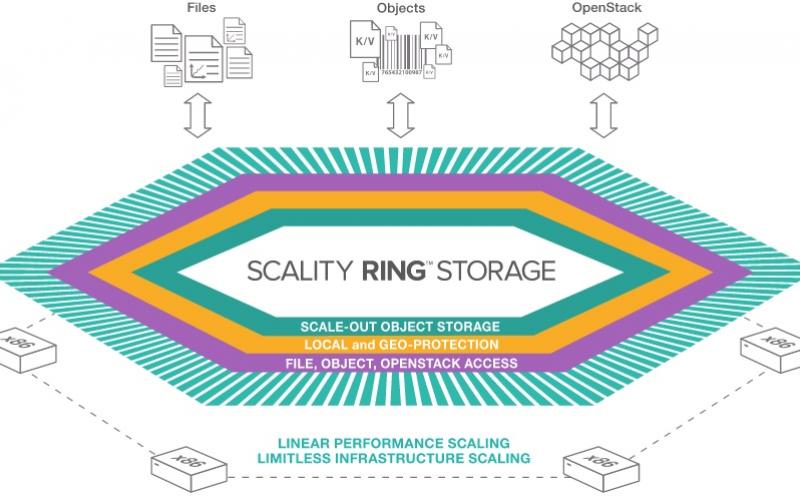
SDS is intended to align storage practices with the orchestrated world of servers and networks in clouds or virtual clusters. The technology moves us away from the current model of proprietary code running on proprietary hardware to an abstracted model where data services run in virtual machines or containers in the server cloud, while actual storage is done using bare-bones COTS appliances.
Underlying this transition to software-defined storage is the realization that today’s storage appliance looks very much like a server. It’s an x86 or ARM CPU with 6 to 12 drives and a lot of networking bandwidth. The logical extension of this transformation away from the monolithic RAID arrays of yore is that the computing functions can be virtualized, leading to the SDS concept.
This virtualization process requires interface standardization for the actual storage devices, so not all of the code migrates into the virtual machines, but features like file systems and management, access tables in object stores, deduplication, compression, erasure coding, encryption and indexing are all becoming virtual services. This should allow flexibility in vendor choices and dynamic sizing of service availability to match changing workloads.
While by no means the only embodiment of SDS, hyperconverged systems are a good way to create the hardware environment needed by melding server and storage appliance functions into a common box type. The result is the ability to position data services and apps where the data is, rather than moving that data to where the apps are. This should speed up operations considerably and will certainly reduce network traffic.
Let’s go under the hood to see what SDS really is about and which vendors are helping deliver on its promise.
(Image: Henrik5000/iStockphoto)